OpenEvolve: Teaching LLMs to Discover Algorithms Through Evolution
How do we teach machines to discover algorithms? Traditional approaches rely on hand-crafted heuristics, exhaustive search, or gradient-based optimization. But what if we could harness the creative potential of large language models (LLMs) within an evolutionary framework?
OpenEvolve is an open-source evolutionary coding agent that integrates large language models into a quality-diversity search framework for algorithm discovery. Candidate programs are produced via LLM-guided edits (diff-based by default), evaluated with user-defined metrics, and organized using MAP-Elites while an island model with migration supports parallel, diversified exploration. The evaluation pipeline supports cascade staging and an artifact side-channel that feeds execution traces and errors back into subsequent prompts; optional LLM-based feedback can be incorporated into scoring.
OpenEvolve has been applied across many domains—here are a few examples: systems optimization, scientific discovery, geospatial algorithms, scaling law discovery, GPU kernel optimization, prompt optimization, and more.
Architecture Overview

Figure 1: OpenEvolve architecture showing the five interconnected components of the evolution loop
The Evolution Loop
- Prompt Sampler: Constructs context-rich prompts by selecting a parent program from the current island and curating evidence sets (top performers by fitness, lineage ancestors, diverse extremes across feature bins, and random samples). Prompts include the parent's code, evaluation metrics, feature coordinates for MAP-Elites, evolution history, and (optionally) execution artifacts. Template selection supports diff-based editing by default or full rewrites, with controlled stochasticity.
- LLM Ensemble: Generates candidate code using a weighted ensemble of OpenAI-compatible models (deterministic under seeds). In standard mode, a model is sampled by weight; in model-based islands, each island uses a fixed model. Responses drive either diff-based edits (SEARCH/REPLACE blocks) or full rewrites (JSON/code-block extraction), with generation parameters drawn from configuration.
- Evaluator: Executes the user-provided
evaluate(program_path)with timeouts and retries; optionally applies cascade evaluation (evaluate_stage1/2/3) with thresholds to filter weak candidates early. It can incorporate LLM-based feedback into metrics and captures artifacts (e.g., stderr, tracebacks) for subsequent prompt context. Parallel evaluations are supported via an internal task pool. - Program Database: Implements MAP-Elites per island, binning programs along configurable feature dimensions (defaults include complexity and diversity; custom dimensions are taken from evaluator metrics). New candidates replace cell occupants when fitness improves (preferring
combined_score, otherwise a safe numeric aggregate excluding feature dimensions). The database enforces population limits, tracks the global best, logs prompts, supports migration, and persists checkpoints. - Controller: Orchestrates the loop, including seeding, logging, prompt/evaluator initialization, and process-based parallel execution. It schedules iterations across islands, manages checkpointing and resume, enforces early stopping/target score criteria, stores artifacts, and writes the best discovered program and its metadata to the output directory.
Key Algorithmic Innovations
Island-Based Evolution with Lazy Migration
OpenEvolve maintains multiple isolated populations (islands) that evolve independently to reduce premature convergence and enable parallel exploration. Migration is event-driven: each island migrates when its per-island program additions since the last migration reach a configured interval, rather than on wall-clock time. Migration follows a ring topology by default (optional random migration), transferring a fraction of top programs while avoiding duplicate code in the destination island.
# Configuration example
database:
num_islands: 5
migration_interval: 20 # generations, not iterations
migration_rate: 0.1 # 10% of top programs migrateMAP-Elites for Diversity Preservation
Each island maintains a MAP-Elites grid over configurable feature dimensions (defaults include complexity and diversity; additional dimensions can be supplied by the evaluator). A candidate occupies or replaces the cell if it improves fitness (preferring combined_score, otherwise a safe aggregate over numeric metrics excluding feature dimensions). This enforces one elite per cell and preserves quality-diversity. The system also avoids exact duplicates (e.g., during migration) and computes diversity using structural measures (e.g., edit distance), rather than relying on code embeddings.
Cascade Evaluation
Evaluation proceeds in stages with configurable thresholds. If cascade functions are provided, Stage 1 performs fast checks (e.g., import/execute), Stage 2 runs lightweight tests, and Stage 3 executes comprehensive benchmarks. Candidates must meet stage thresholds to advance. Timeouts and exceptions are captured as artifacts and can be fed back into subsequent prompts. When cascade functions are not defined, evaluation falls back to a single-stage evaluate(program_path) with timeouts and retries.
Double-Selection Strategy
Parent selection is biased toward high-fitness programs, while inspiration material shown to the LLM is drawn from complementary sources (top programs, lineage ancestors, diverse extremes across feature bins, and random samples). This separation encourages improvements guided by the current best while maintaining exploration pressure via diverse exemplars, implemented through prompt construction rather than direct recombination.
Sample Use Cases
Example 1: Algorithmic Discovery
On the AlgoTune benchmark, OpenEvolve discovered algorithms achieving dramatic speedups through automatic optimization:
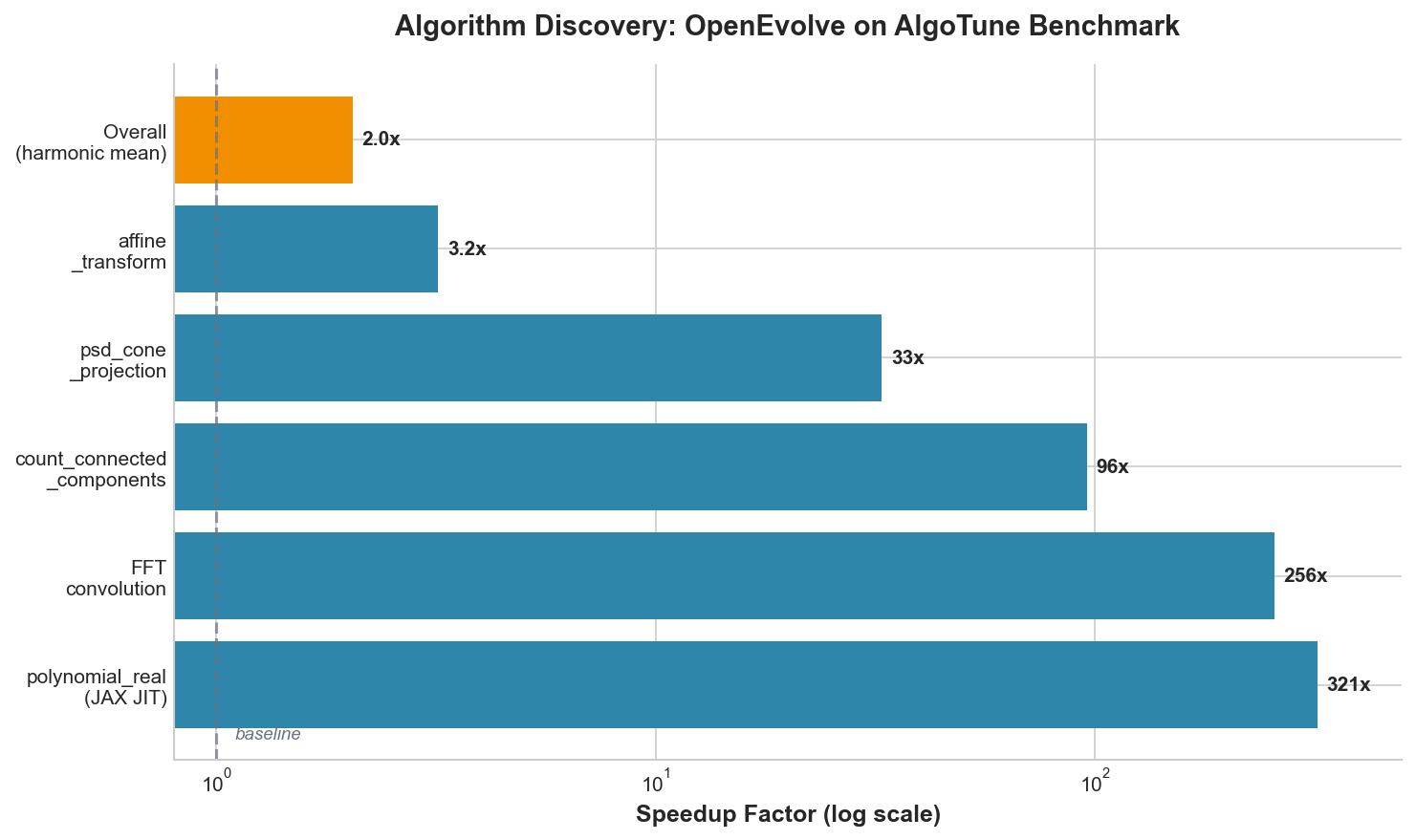
Figure 2: Algorithmic discovery results showing dramatic speedups on the AlgoTune benchmark
Key breakthroughs include automatic discovery of JAX JIT compilation (321x), FFT-based convolution (256x), and optimized graph algorithms (95.78x). The system evolved from simple iterative implementations to sophisticated numerical computing patterns without human intervention. For more detailed analysis, see Towards Open Evolutionary Agents.
Example 2: Circle Packing
OpenEvolve matched state-of-the-art results (2.634 sum of radii for n=26), evolving from naive geometric constructions to discovering scipy.optimize with SLSQP—a completely different algorithmic approach than the initial solution.
Example 3: GPU Kernel Optimization
Evolution of Metal GPU kernels for transformer attention on Apple Silicon:
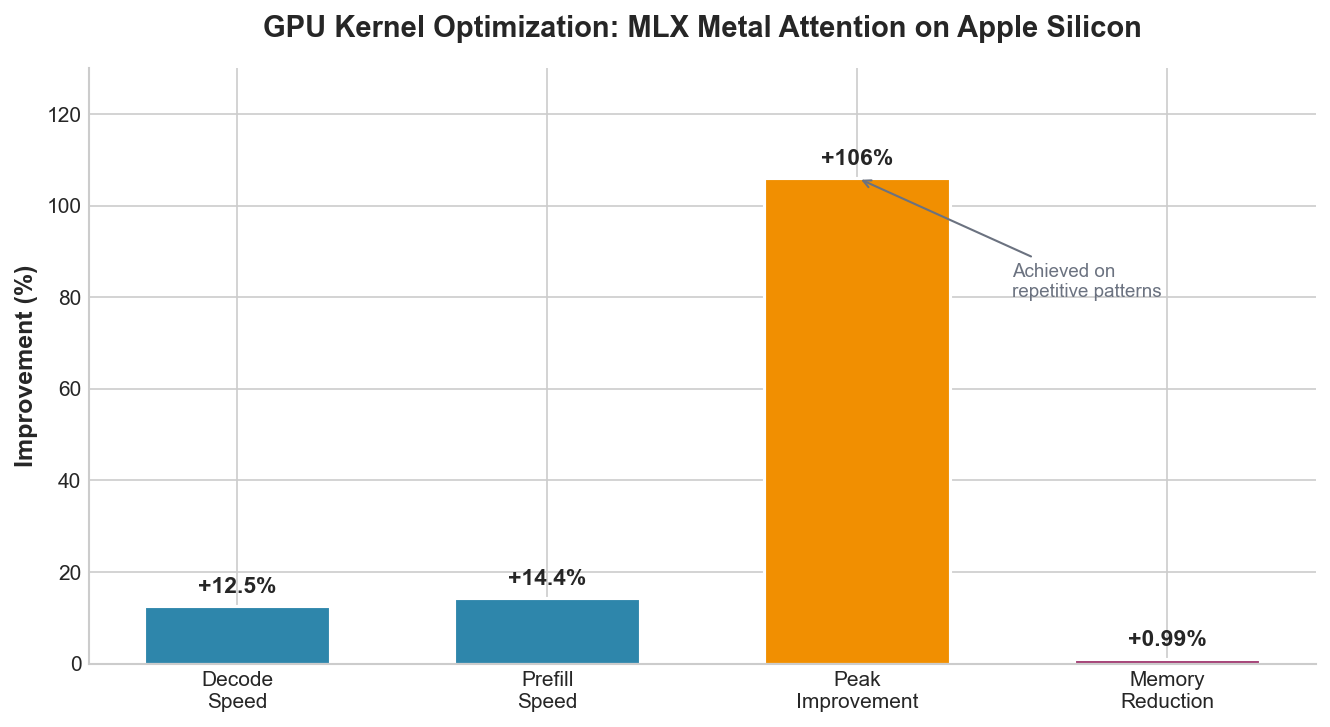
Figure 3: GPU kernel performance improvements for transformer attention on Apple Silicon
OpenEvolve discovered several non-obvious optimizations:
- 8-element SIMD vectorization matching Apple Silicon's hardware width
- Two-pass online softmax reducing memory bandwidth
- GQA-specific memory layouts exploiting head structure
These optimizations maintain 100% numerical accuracy while achieving measurable performance improvements across diverse inference scenarios. For more details, see GPU Kernel Discovery.
Example 4: LLM Prompt Optimization
Beyond code, OpenEvolve can evolve prompts themselves:
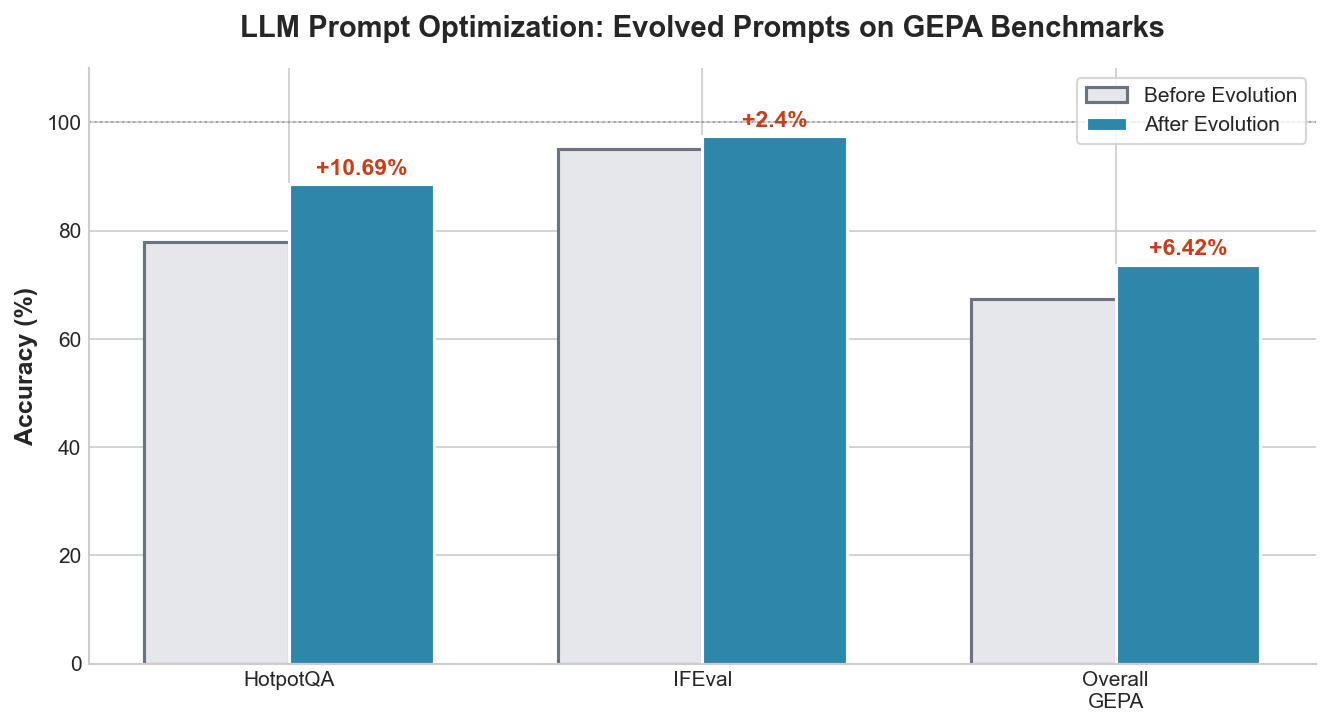
Figure 4: Prompt optimization results on GEPA benchmarks
On GEPA benchmarks, evolved prompts achieved +10.69% accuracy on HotpotQA (multi-hop reasoning) and +6.42% overall across multiple benchmarks. This demonstrates OpenEvolve's versatility—the same evolutionary framework optimizes both code and natural language.
Evolution Progress: As shown below on the AlgoTune benchmark, we see that the performance consistently improves over generations. Extended evolution (200 iterations) achieved 24% better results than shorter runs (100 iterations), suggesting that patient exploration of the solution space yields compounding benefits.
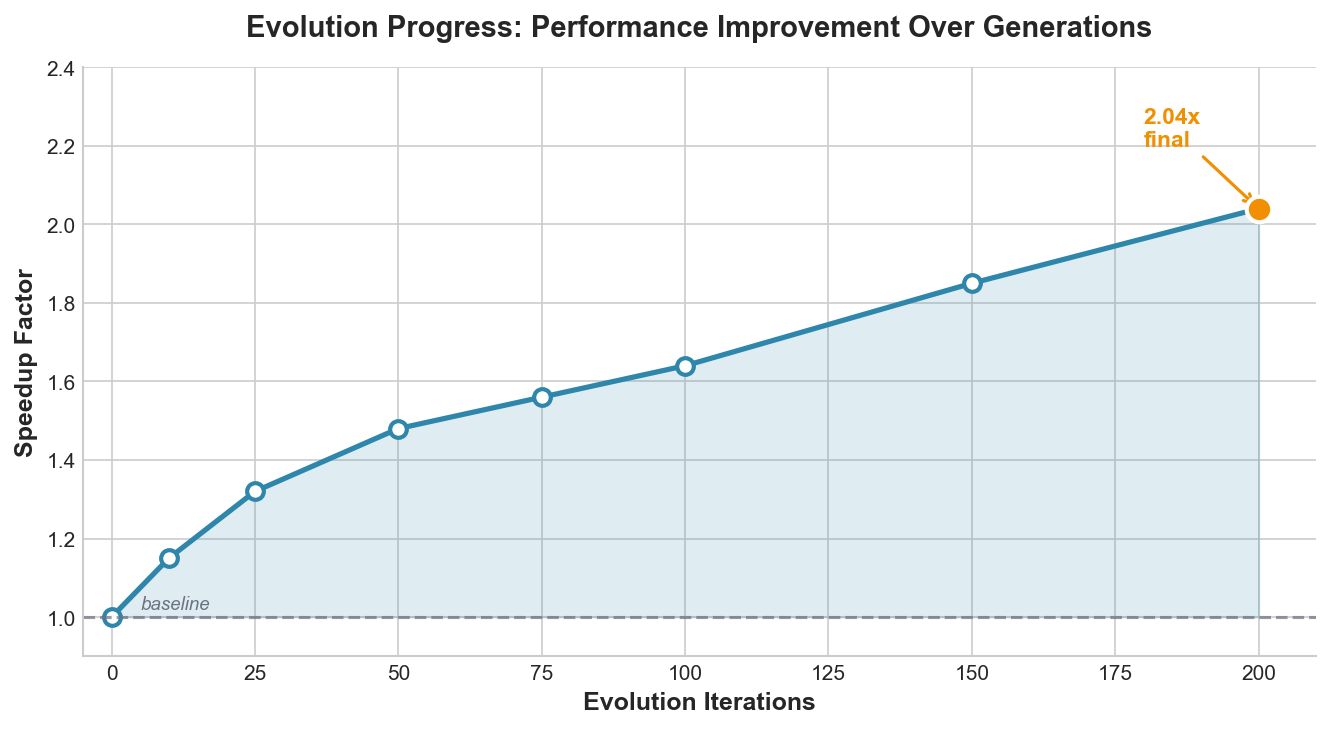
Figure 5: Performance improvement over generations showing compounding benefits of extended evolution
Getting Started
OpenEvolve provides both library and command-line interfaces:
from openevolve import run_evolution
result = run_evolution(
initial_program="def solve(x): return x * 2",
evaluator=lambda path: {"score": benchmark(path)},
iterations=100
)For complex configurations, use YAML files specifying LLM models, evolution strategies, and evaluation parameters. OpenEvolve supports checkpoint/resume for long-running experiments and parallel evaluation across multiple cores. OpenEvolve is open-source and available on GitHub.
Update: This blog post was updated on November 1, 2025